PUBLICATION
CoLLAs 24
Adaptive Action Advising with Different Rewards
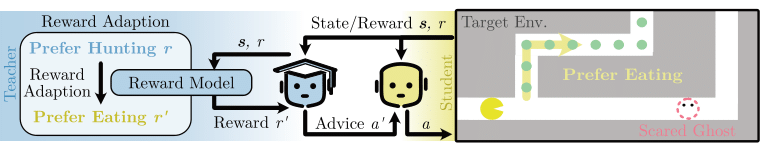
Action advising is a critical aspect of reinforcement learning, involving a teacher-student paradigm wherein the teacher, possessing a pre-trained policy, advises the student with the actions calculated from its policy based on the latter's observations, thereby improving the student's task performance. An important requirement is for the teacher to be able to learn to robustly adapt and give effective advice in new environments where the reward is different from the one the teacher has been trained on. This issue has not been considered in the current teacher-student literature, therefore, most of the work require the teacher to be pre-trained with the same reward that the student interacts with and cannot generalize advice that differs from the policy; the reward that the student gained through interaction with the environment is also directly given to the teacher, regardless the exploration process. To fill this gap, our proposed method enhances action advising by allowing the teacher to learn by observing and collecting data from the student and adapting its reward function. We empirically evaluate our method over three environments consisting of a Gridworld, an ALE skiing, and a Pacman, and our method demonstrates improved policy returns and sample efficiency.
Guo, Y., Zhang, X., Stepputtis, S., Campbell, J., & Sycara, K. (2023, August). Adaptive Action Advising with Different Rewards. In 2024 Conference on Lifelong Learning Agents (CoLLAs).
ICRA 23
Explainable Action Advising for Multi-Agent Reinforcement Learning
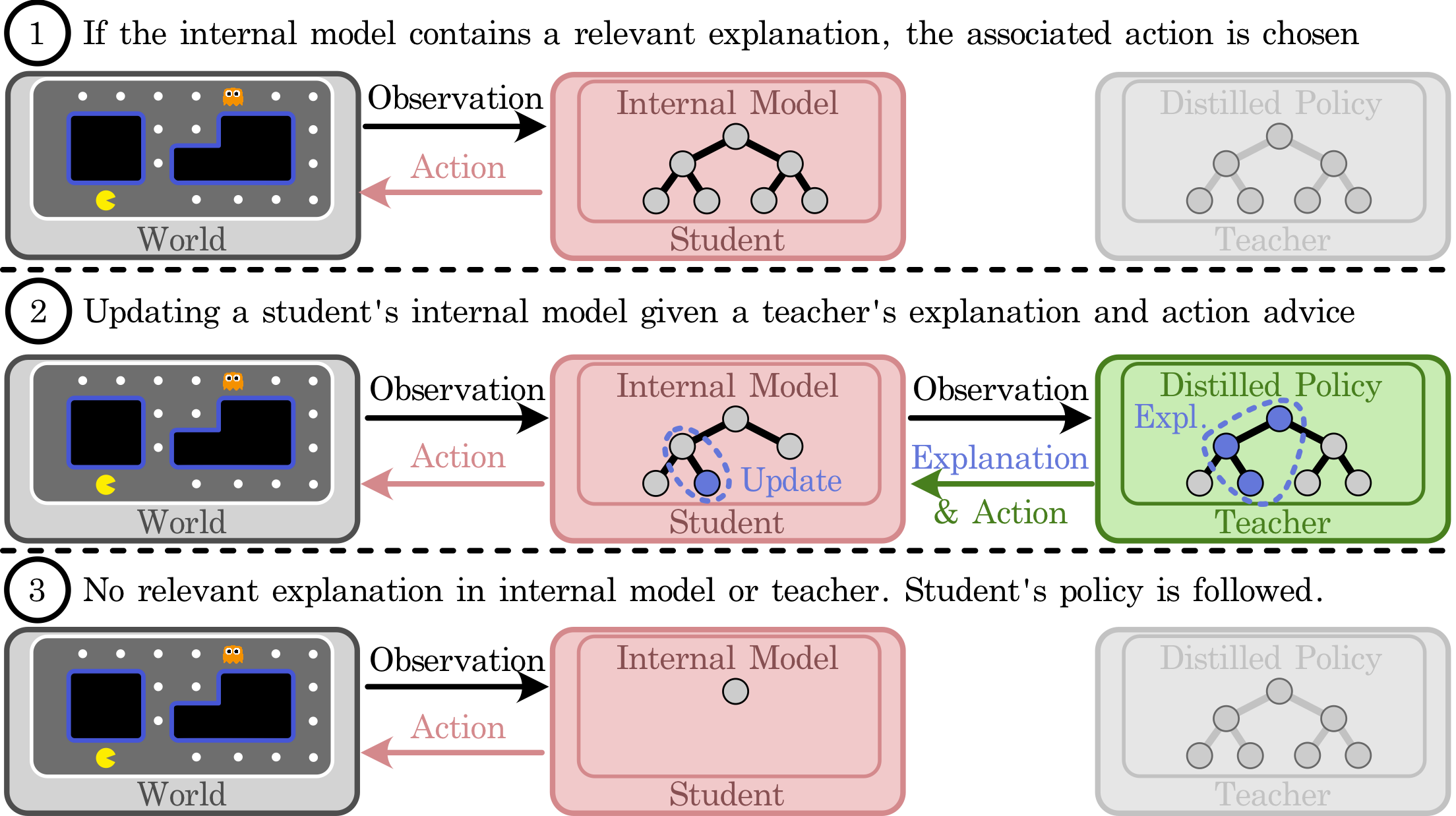
Action advising is a knowledge transfer technique for reinforcement learning based on the teacher-student paradigm. An expert teacher provides advice to a student during training in order to improve the student's sample efficiency and policy performance. Such advice is commonly given in the form of state-action pairs. However, it makes it difficult for the student to reason with and apply to novel states. We introduce Explainable Action Advising, in which the teacher provides action advice as well as associated explanations indicating why the action was chosen. This allows the student to self-reflect on what it has learned, enabling advice generalization and leading to improved sample efficiency and learning performance -- even in environments where the teacher is sub-optimal. We empirically show that our framework is effective in both single-agent and multi-agent scenarios, yielding improved policy returns and convergence rates when compared to state-of-the-art methods.
Guo, Y., Campbell, J., Stepputtis, S., Li, R., Hughes, D., Fang, F., & Sycara, K. (2023, June). Explainable Action Advising for Multi-Agent Reinforcement Learning. In 2023 IEEE International Conference on Robotics and Automation (ICRA) (pp. 5515-5521). IEEE.
CoLLAs 23
Introspective Action Advising for Interpretable Transfer Learning
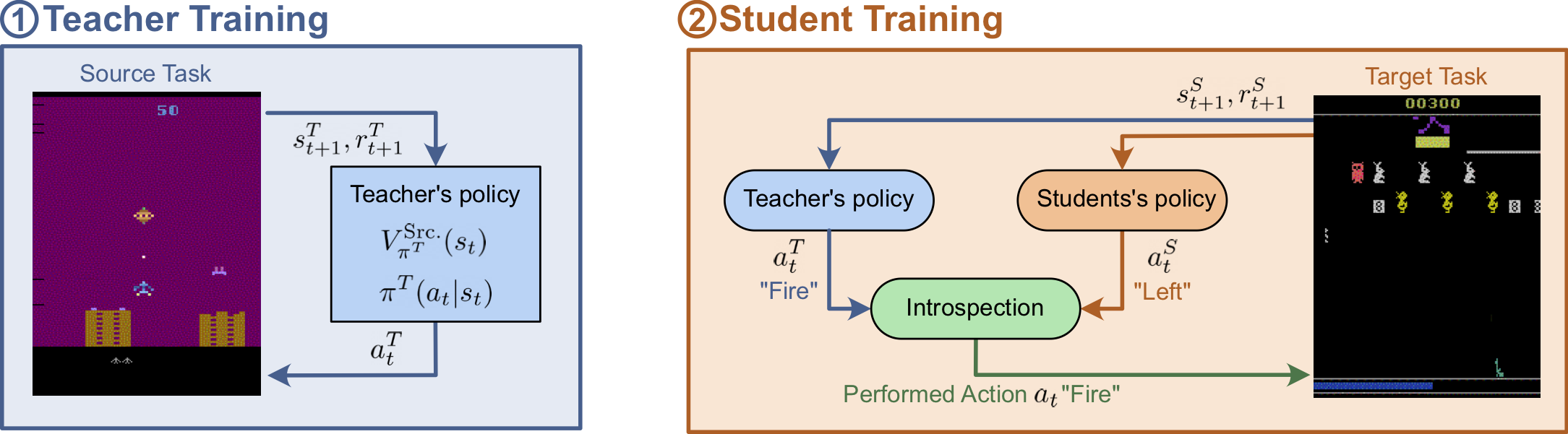
Transfer learning can be applied in deep reinforcement learning to accelerate the training of a policy in a target task by transferring knowledge from a policy learned in a related source task. This is commonly achieved by copying pretrained weights from the source policy to the target policy prior to training, under the constraint that they use the same model architecture. However, not only does this require a robust representation learned over a wide distribution of states -- often failing to transfer between specialist models trained over single tasks -- but it is largely uninterpretable and provides little indication of what knowledge is transferred. In this work, we propose an alternative approach to transfer learning between tasks based on action advising, in which a teacher trained in a source task actively guides a student's exploration in a target task. Through introspection, the teacher is capable of identifying when advice is beneficial to the student and should be given, and when it is not. Our approach allows knowledge transfer between policies agnostic of the underlying representations, and we empirically show that this leads to improved convergence rates in Gridworld and Atari environments while providing insight into what knowledge is transferred.
Campbell, J., Guo, Y., Xie, F., Stepputtis, S., & Sycara, K. (2023, August). Introspective Action Advising for Interpretable Transfer Learning. In 2023 Conference on Lifelong Learning Agents (CoLLAs).
US Patent 23
Reinforcement Learning Techniques for Network-Based Transfer Learning
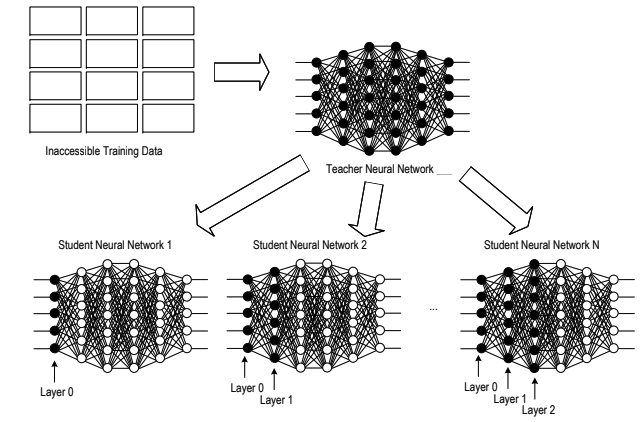
Various vehicles employ computing means to aid automated vehicle operation. Recently, in the automotive industry, much of the focus is on making a vehicle operate in an autonomous mode in a safe manner. Many autonomous vehicle systems employ predictive models (e.g., neural networks) that, given various sensor input captured at the vehicle, predict a future driving situation (e.g., a lane change, a cut in, etc.). In response to the predicted situation, a corresponding action (e.g. reduce speed, change lanes, etc.) may be selected for the autonomous vehicle in question and actuators of the vehicle may be controlled to carry out the action. Training these, and other, predictive models can be time consuming and complicated and may require many instances of training data to produce an acceptably accurate predictive model. Data obtained in one domain may include features that may be less helpful, or completely unhelpful, in a different domain. Additionally, training data of one domain may be restricted from use in another domain. Embodiments are directed to addressing these and other problems, individually and collectively.
Guo, Y., Yang, I., Wang, Y. US11657280B1.
Intelligence & Robotics 23
Reinforcement Learning Methods for Network-Based Transfer Parameter Selection
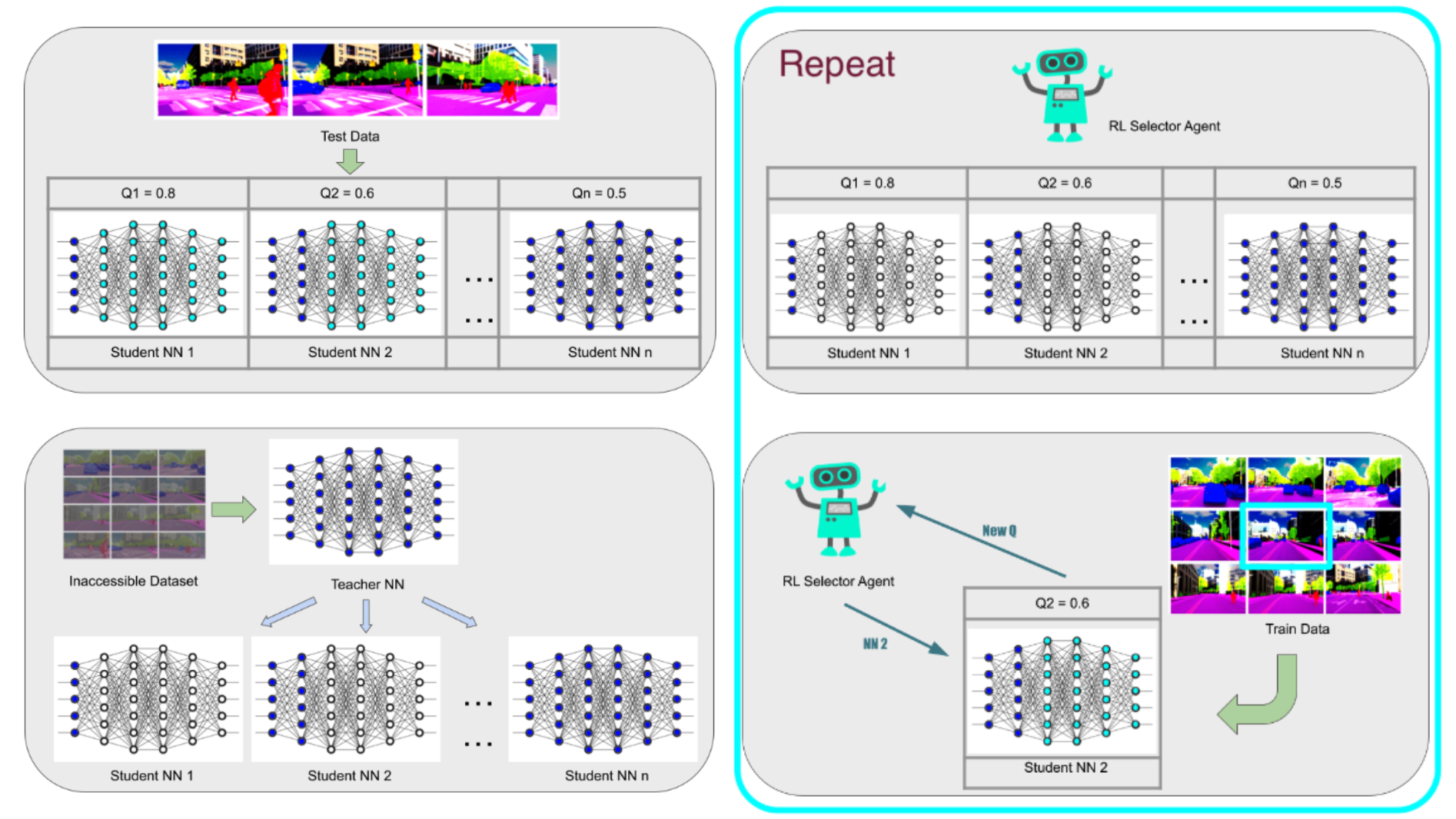
A significant challenge in self-driving technology involves the domain-specific training of prediction models on inten- tions of other surrounding vehicles. Separately processing domain-specific models requires substantial human re- sources, time, and equipment for data collection and training. For instance, substantial difficulties arise when directly applying a prediction model developed with data from China to the United States market due to complex factors such as differing driving behaviors and traffic rules. The emergence of transfer learning seems to offer solutions, enabling the reuse of models and data to enhance prediction efficiency across international markets. However, many transfer learning methods require a comparison between source and target data domains to determine what can be trans- ferred, a process that can often be legally restricted. A specialized area of transfer learning, known as network-based transfer, could potentially provide a solution. This approach involves pre-training and fine-tuning ”student” models using selected parameters from a ”teacher” model. However, as networks typically have a large number of parame- ters, it raises questions about the most efficient methods for parameter selection to optimize transfer learning. An automatic parameter selector through reinforcement learning has been developed in this paper, named ”Automatic Transfer Selector via Reinforcement Learning”. This technique enhances the efficiency of parameter selection for transfer prediction between international self-driving markets, in contrast to manual methods. With this innovative approach, technicians are relieved from the labor-intensive task of testing each parameter combination, or endur- ing lengthy training periods to evaluate the impact of prediction transfer. Experiments have been conducted using a temporal convolutional neural network fully trained with the data from the Chinese market and one month’s US data, focusing on improving the training efficiency of specific driving scenarios in the US. Results show that the proposed approach significantly improves the prediction transfer process.
Guo Y, Wang Y, Yang IH, Sycara K. Reinforcement learning methods for network-based transfer parameter selection. Intell Robot 2023;3(3):402-19. http://dx.doi.org/10.20517/ir.2023.23
RO-MAN 21
Transfer Learning for Human Navigation and Triage Strategies Prediction in a Simulated Urban Search and Rescue Task
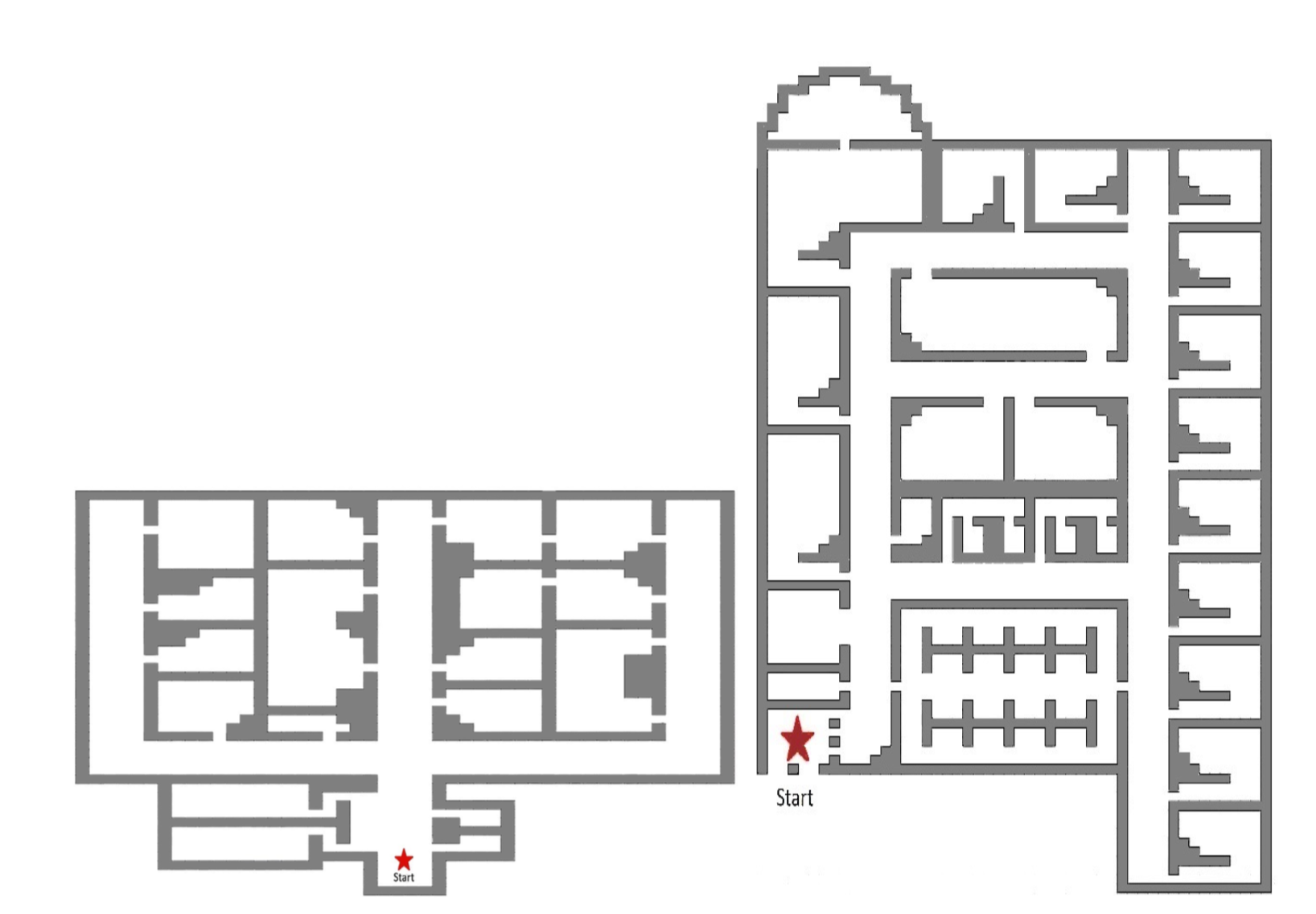
To build an agent providing assistance to human rescuers in an urban search and rescue task, it is crucial to understand not only human actions but also human beliefs that may influence the decision to take these actions. Developing data-driven models to predict a rescuer’s strategies for navigating the environment and triaging victims requires costly data collection and training for each new environment of interest. Transfer learning approaches can be used to mitigate this challenge, allowing a model trained on a source environment/task to generalize to a previously unseen target environment/task with few training examples. In this paper, we investigate transfer learning (a) from a source environment with smaller number of types of injured victims to one with larger number of victim injury classes and (b) from a smaller and simpler environment to a larger and more complex one for navigation strategy. Inspired by hierarchical organization of human spatial cognition, we used graph division to represent spatial knowledge, and Transfer Learning Diffusion Convo- lutional Recurrent Neural Network (TL-DCRNN), a spatial and temporal graph-based recurrent neural network suitable for transfer learning, to predict navigation. To abstract the rescue strategy from a rescuer’s field-of-view stream, we used attention-based LSTM networks. We experimented on various transfer learning scenarios and evaluated the performance using mean average error. Results indicated our assistant agent can improve predictive accuracy and learn target tasks faster when equipped with transfer learning methods.
Guo, Y., Jena, R., Hughes, D., Lewis, M., & Sycara, K. (2021, August). Transfer Learning for Human Navigation and Triage Strategies Prediction in a Simulated Urban Search and Rescue Task. In 2021 30th IEEE International Conference on Robot & Human Interactive Communication (RO-MAN) (pp. 784-791). IEEE.
RO-MAN 20a
Designing Context-Sensitive Norm Inverse Reinforcement Learning Framework for Norm-Compliant Autonomous Agents
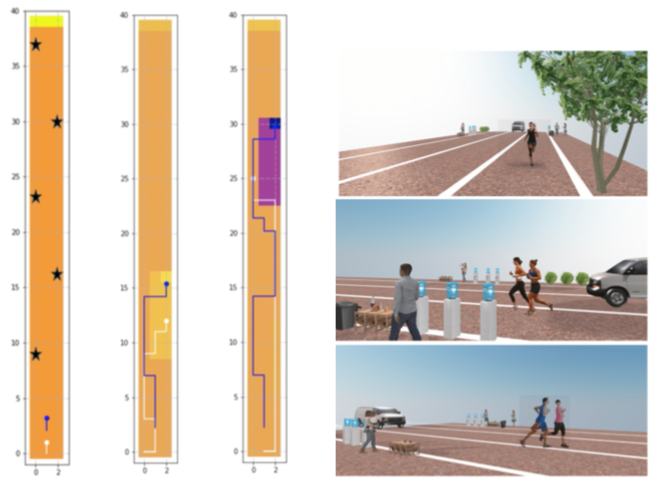
Human behaviors are often prohibited, or permit- ted by social norms. Therefore, if autonomous agents interact with humans, they also need to reason about various legal rules, social and ethical social norms, so they would be trusted and accepted by humans. Inverse Reinforcement Learning (IRL) can be used for the autonomous agents to learn social norm-compliant behavior via expert demonstrations. However, norms are context-sensitive, i.e. different norms get activated in different contexts. For example, the privacy norm is activated for a domestic robot entering a bathroom where a person may be present, whereas it is not activated for the robot entering the kitchen. Representing various contexts in the state space of the robot, as well as getting expert demonstrations under all possible tasks and contexts is extremely challenging. Inspired by recent work on Modularized Normative MDP (MNMDP) and early work on context-sensitive RL, we propose a new IRL framework, Context-Sensitive Norm IRL (CNIRL). CNIRL treats states and contexts separately, and assumes that the expert determines the priority of every possible norm in the environment, where each norm is associated with a distinct reward function. The agent chooses the action to maximize its cumulative rewards. We present the CNIRL model and show that its computational complexity is scalable in the number of norms. We also show via two experimental scenarios that CNIRL can handle problems with changing context spaces.
Guo, Y., Wang, B., Hughes, D., Lewis, M., & Sycara, K. (2020). Designing Context-Sensitive Norm Inverse Reinforcement Learning Framework for Norm-Compliant Autonomous Agents. In 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN) (pp. 618-625). IEEE.
RO-MAN 20b
Inferring Non-Stationary Human Preferences for Human-Agent Teams

One main challenge to robot decision making in human-robot teams involves predicting the intents of a human team member through observations of the human’s behavior. Inverse Reinforcement Learning (IRL) is one approach to predicting human intent, however, such approaches typically assume that the human’s intent is stationary. Furthermore, there are few approaches that identify when the human’s intent changes during observations. Modeling human decision making as a Markov decision process, we address these two limitations by maintaining a belief over the reward parameters of the model (representing the human’s preference for tasks or goals), and updating the parameters using IRL estimates from short windows of observations. We posit that a human’s preferences can change with time, due to gradual drift of preference and/or discrete, step-wise changes of intent. Our approach maintains an estimate of the human’s preferences under such conditions, and is able to identify changes of intent based on the divergence between subsequent belief updates. We demonstrate that our approach can effectively track dynamic reward parameters and identify changes of intent in a simulated environment, and that this approach can be leveraged by a robot team member to improve team performance.
Hughes, D., Agarwal, A., Guo, Y., & Sycara, K. (2020). Inferring Non-Stationary Human Preferences for Human-Agent Teams. In 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN) (pp. 1178-1185). IEEE.
In Submission
A Computational Framework for Norm-Aware Reasoning for Autonomous Systems
Autonomous agents are increasingly deployed in complex social environments where they not only have to reason about their domain goals but also about the norms that can impose constraints on task performance. The intelligent trade-offs that these systems must make between domain and normative constraints is the key to their acceptance as socially responsible agents in the community. Integrating task planning with norm aware reasoning is a challenging problem due to the curse of dimensionality associated with product spaces of the domain state variables and norm-related variables. To this end, we propose a Modular Normative Markov Decision Process (MNMDP) framework that is shown to have orders of magnitude increase in performance compared to previous approaches. Because norms are both context-dependent and context-sensitive, context must be modeled effectively in order to find activation and deactivation conditions for norms. To this end, we propose an expressive, scalable and generalizable context modeling approach to understand norm activations in social environments combining the expressivity of propositional logic with the compactness of decision trees. We show how we can combine our context model with our MNMDP framework to support norm understanding as well as norm enforcement for real systems. Human experiments were conducted to collect data relating context and norms to populate our framework. We discuss the results and inferences obtained from these data confirming the complexity of the relationship between contexts and norms and the necessity of empirical data to building a scalable norm-aware reasoning frame- work for autonomous systems. We demonstrate our approach through scenarios in simulated social environments in which agents using the framework display norm-aware behavior. In order to discover which norms get activated in various contexts and with what priorities, we performed a set of extensive human experiments and show how these results constitute the basis for building context-based norm aware systems.
Bachelor Sc. Honors Thesis
Finding Optimal Strategies over Families of Tasks in Reinforcement Learning
In reinforcement learning, the transition and reward functions are typically unknown but stationary. The agent must interact with the environment to gather information about the unknown transition and reward functions to maximize overall reward.When we are faced with a new problem with an unknown transition function, which is drawn from the same distribution that prior problems were drawn from, we want to speed learning by using knowledge of prior problems. We also want to focus on building the whole policy in advance, i.e., using past knowledge to compute (perhaps using a lot of computation time) a policy that we can then deploy in real life easily.
In order to explore, we further simplify the problem by assuming the changing transition func- tions are deterministic and of unknown but fixed distribution, with the reward function R unknown but fixed. We hope that through examining this situation, we could gain some insights into dealing with changing transition functions in real world. We also hope that by finding optimal strategies in this situation, we could further explore the situation when both R and T change.
Guo, Y., Abel, D., Jinnai, Y., Konidaris, G., & Littman, M. (2018). Finding Optimal Strategies over Families of Tasks in Reinforcement Learning. Brown University Applied Math - Computer Science Sc.B Honors Thesis.
ICML 18
Policy and Value Transfer in Lifelong Reinforcement Learning
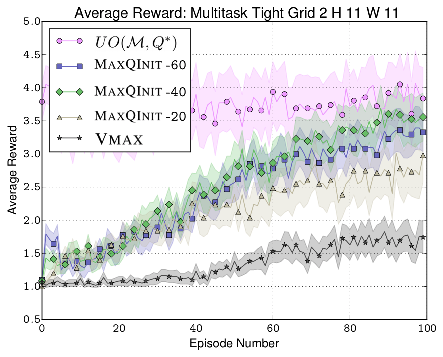
We consider the problem of how best to use prior experience to bootstrap lifelong learning, where an agent faces a series of task instances drawn from some task distribution. First, we identify the initial policy that optimizes expected performance over the distribution of tasks for increasingly complex classes of policy and task distributions. We empirically demonstrate the relative performance of each policy class’ optimal element in a variety of simple task distributions. We then con- sider value-function initialization methods that preserve PAC guarantees while simultaneously minimizing the learning required in two learn- ing algorithms, yielding MAXQINIT, a practical new method for value-function-based transfer. We show that MAXQINIT performs well in simple lifelong RL experiments.
Abel, D., Jinnai, Y., Guo, S. Y., Konidaris, G., & Littman, M. (2018, July). Policy and value transfer in lifelong reinforcement learning. In International Conference on Machine Learning (pp. 20-29). PMLR.
HILDA 17
What you see is not what you get! Detecting Simpson’s Paradoxes during Data Exploration
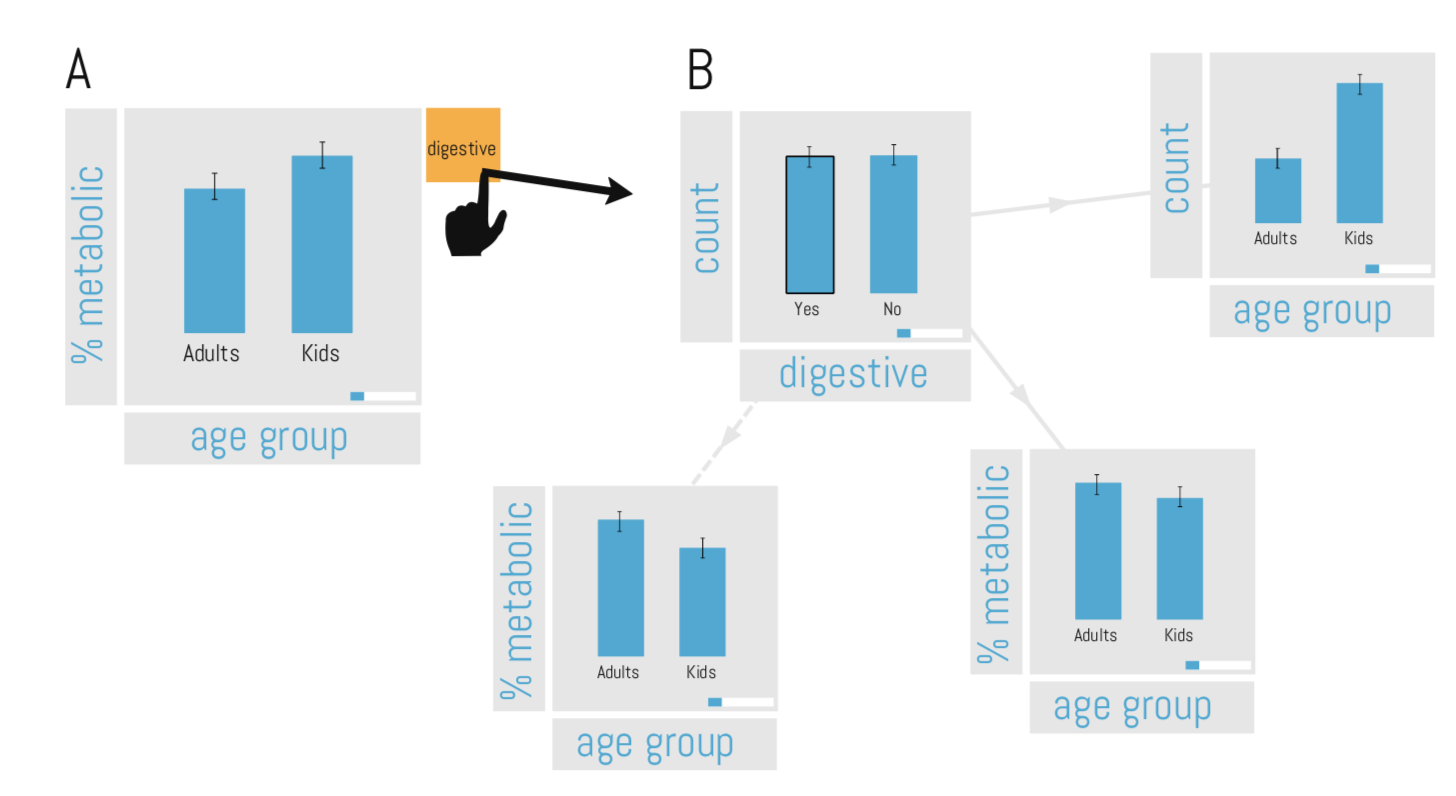
Visual data exploration tools, such as Vizdom or Tableau, significantly simplify data exploration for domain experts and, more importantly, novice users. These tools allow to discover complex correlations and to test hypotheses and differences between various populations in an entirely visual manner with just a few clicks, unfortunately, often ignoring even the most basic statistical rules. For example, there are many statistical pitfalls that a user can “tap” into when exploring data sets. As a result of this experience, we started to build QUDE, the first system to Quantifying the Uncertainty in Data Exploration, which is part of Brown’s Interactive Data Exploration Stack (called IDES). The goal of QUDE is to automatically warn and, if possible, protect users from common mistakes during the data exploration process. In this paper, we focus on a different type of error, the Simpson’s Paradox, which is a special type of error in which a high-level aggregate/visualization leads to the wrong conclusion since a trend reverts when splitting the visualized data set into multiple subgroups (i.e., when executing a drill-down).
Guo, Y., Binnig, C., & Kraska, T. (2017, May). What you see is not what you get! Detecting Simpson's Paradoxes during Data Exploration. In Proceedings of the 2nd Workshop on Human-In-the-Loop Data Analytics (pp. 1-5).
